Welcome, Heterogeneous Intelligence
The hardest problems in AI are not single-step questions with clear answers. They are long-horizon, multi-turn and open-ended - unfolding across environments that change with every interaction. They are also naturally heterogeneous; they need diverse reasoning and action with agents that explore, verify, synthesise and act on the world, coordinating in real time to collectively solve problems no single agent could handle alone. To have real economic impact, these problems must be solved quickly and cheaply - often simultaneously. This is a systems problem requiring the coordination of interacting models, not just an individual model in isolation.
Today we're sharing early discoveries from the infrastructure we built to solve these kinds of problems - infrastructure that co-evolves heterogeneous chips and intelligence, charting a new direction for AI compute. Here we demonstrate results across today's heterogeneous silicon including AWS Trainium, Cerebras, SambaNova, and others.
Callosum is a vertically integrated Intelligent System: dynamic workflows and agents optimised down to kernels and silicon. Our workflows are aware of the hardware they're running on. Our models are aware of the task graph they're serving. Our kernels are aware of the output constraints the workflow requires. Every layer sees the others, each one co-optimised in context of the whole - across heterogeneous models and heterogeneous chips simultaneously. Our conviction is that the next substantial leaps in AI capability, cost and speed will come from this heterogeneity - mixed models on mixed hardware, orchestrated end-to-end, co-evolved to exploit their differences. We call this paradigm Heterogeneous Intelligence.
Across four categories of problems - Deep context, Open web, Cache-intensive and Tool calling - we break state-of-the-art, delivering fundamental improvements in cost and speed, through a single stack. Our infrastructure makes it possible to flexibly tailor capability, speed and cost to optimise for the particular objectives of the user. In many cases, this unlocks orders-of-magnitude improvements, turning benchmark capabilities into systems that are economically viable solutions for real-world challenges. Keep in mind, this is the worst our infrastructure will ever be.
Heterogeneous recursion uses mixed models and mixed silicon to solve long-chain reasoning faster and cheaper than any single configuration.
Deep context problems are everywhere in production AI: sifting through large, dynamically changing bodies of information, crunching databases requiring sustained reasoning over each entry, rapidly selecting task-relevant information at the timescale the task demands. The context itself becomes an environment to be actively explored, as it needs to be chunked, navigated, and reasoned over.
A single workflow here contains fundamentally different kinds of computation: rapid generation, deep retrieval, long-range coherence verification, branching evaluation. Each has a different memory profile, a different latency requirement, a different optimal hardware target.
We decompose these workflows across a hierarchy of recursive language models (RLMs), which - in the naive case - are models that call themselves iteratively to solve problems beyond the reach of a single forward pass, generating partial results, evaluating them, then recursing to refine, expand, or branch. Heterogeneous recursion takes this further: rather than one model recursively calling the same model on the same hardware, we decompose the recursion across a deliberately-selected & diverse set of models and silicon. A seed model sets the plan and coherence constraints while sub-models handle the expansion, retrieval, and verification, each dispatched to the hardware that fits its compute profile.
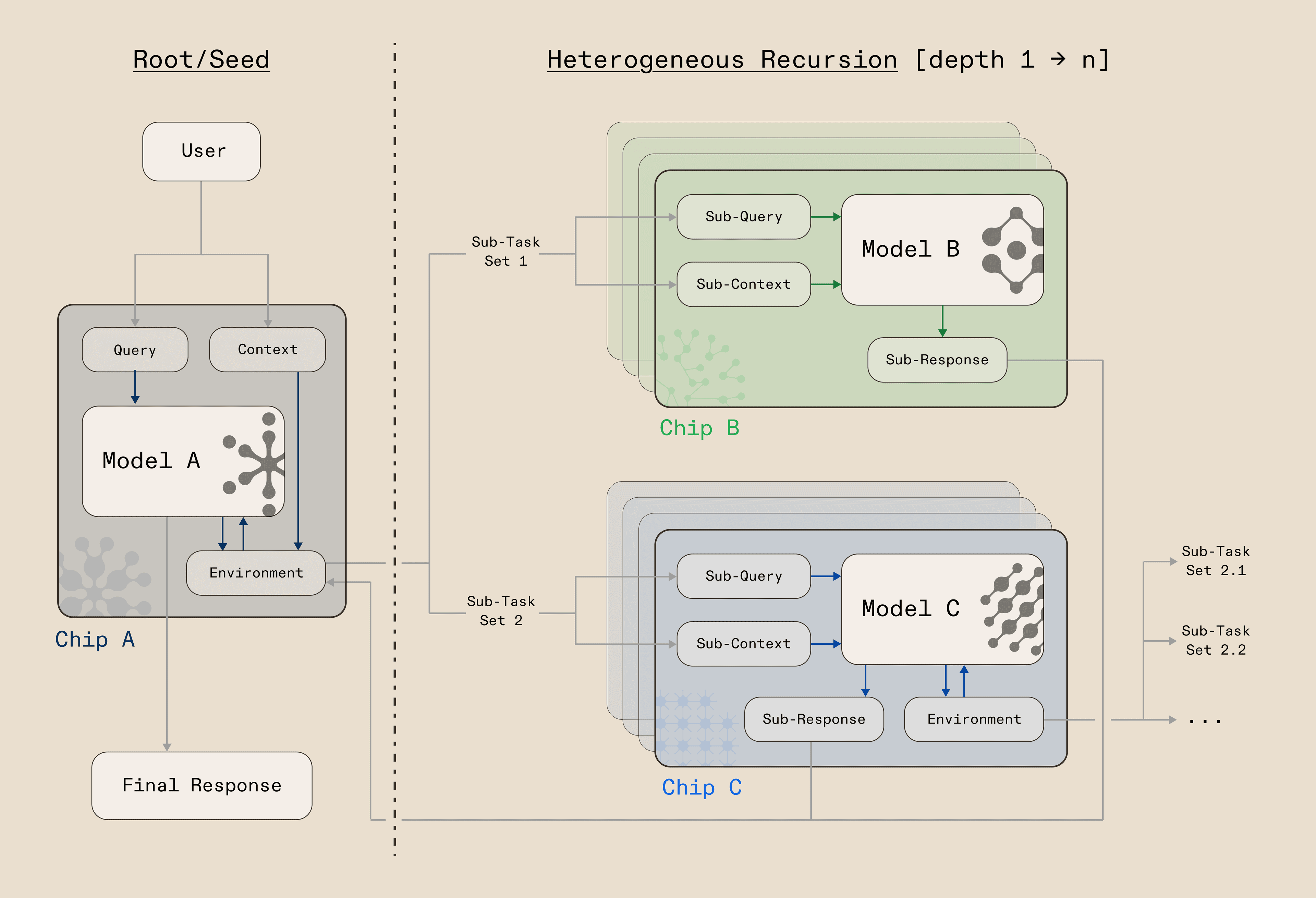
We found that the way you partition the recursion: which model handles which level, on which chip, and at which point in the reasoning chain, matters more than the raw capability of any individual component. Get the decomposition right, and you can unlock frontier-level performance at a fraction of the cost and speed.
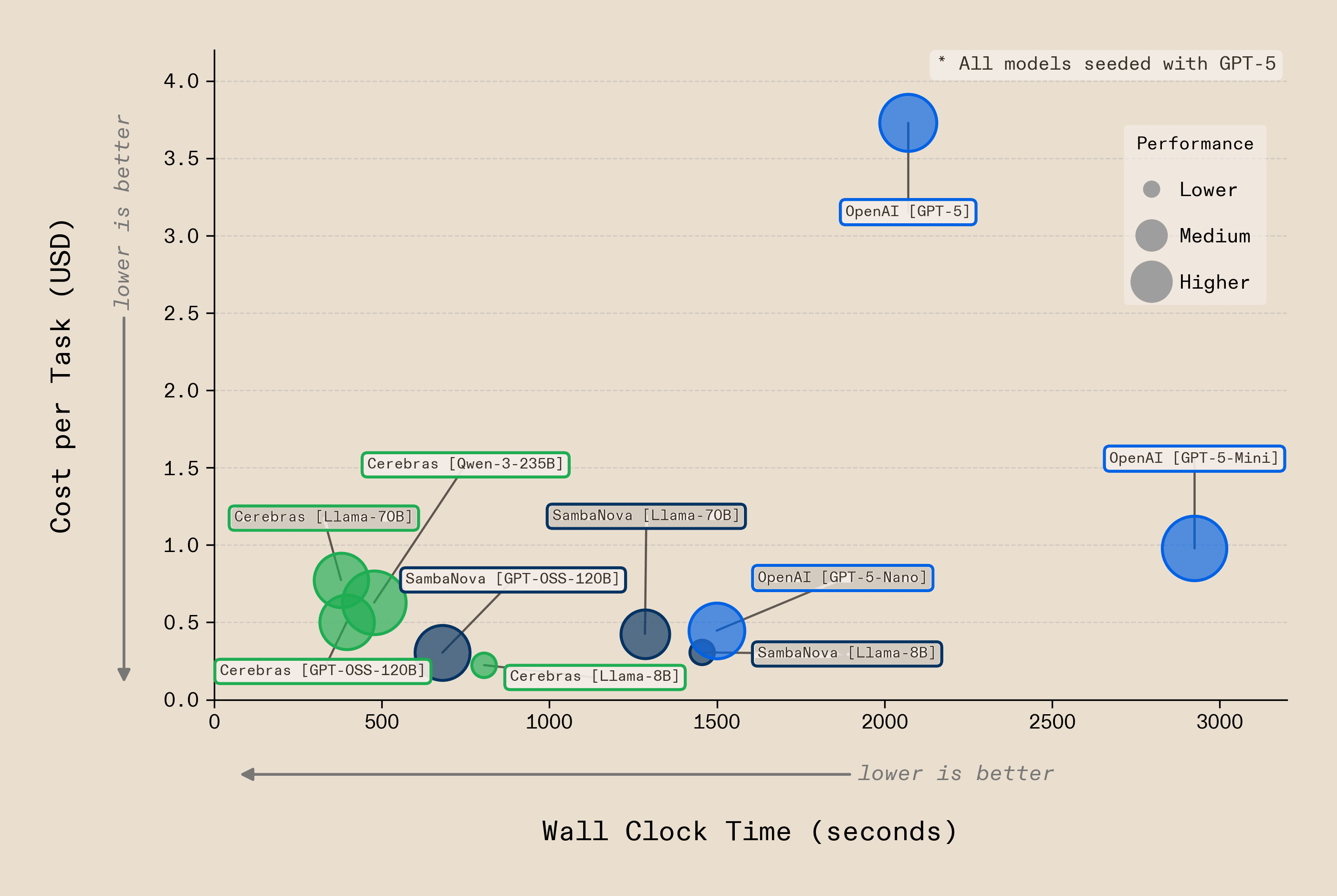
By enabling heterogeneous recursion across a flexible range of configurations (many different models, at different depths, on distinct silicon) we unlock a configuration space that single-model systems can't access. We found that many configurations achieve comparable accuracy, but at very different price and speed points. Cerebras Llama-70B delivers the same accuracy at 5.5x the speed and 4.8x lower cost than GPT-5 as a recursive language model. SambaNova Llama-70B matches it at 8.8x lower cost. Cerebras GPT-OSS-120B delivers the same accuracy at 5x the speed and 7x lower cost than GPT-5. SambaNova GPT-OSS-120B matches that accuracy at 12x lower cost. No single configuration dominates across every objective. Our infrastructure discovers these differences automatically across the OOLONG dataset, routing each phase of the workflow to the silicon where it performs best and giving the user the ability to optimise for the tradeoff that matters to them.
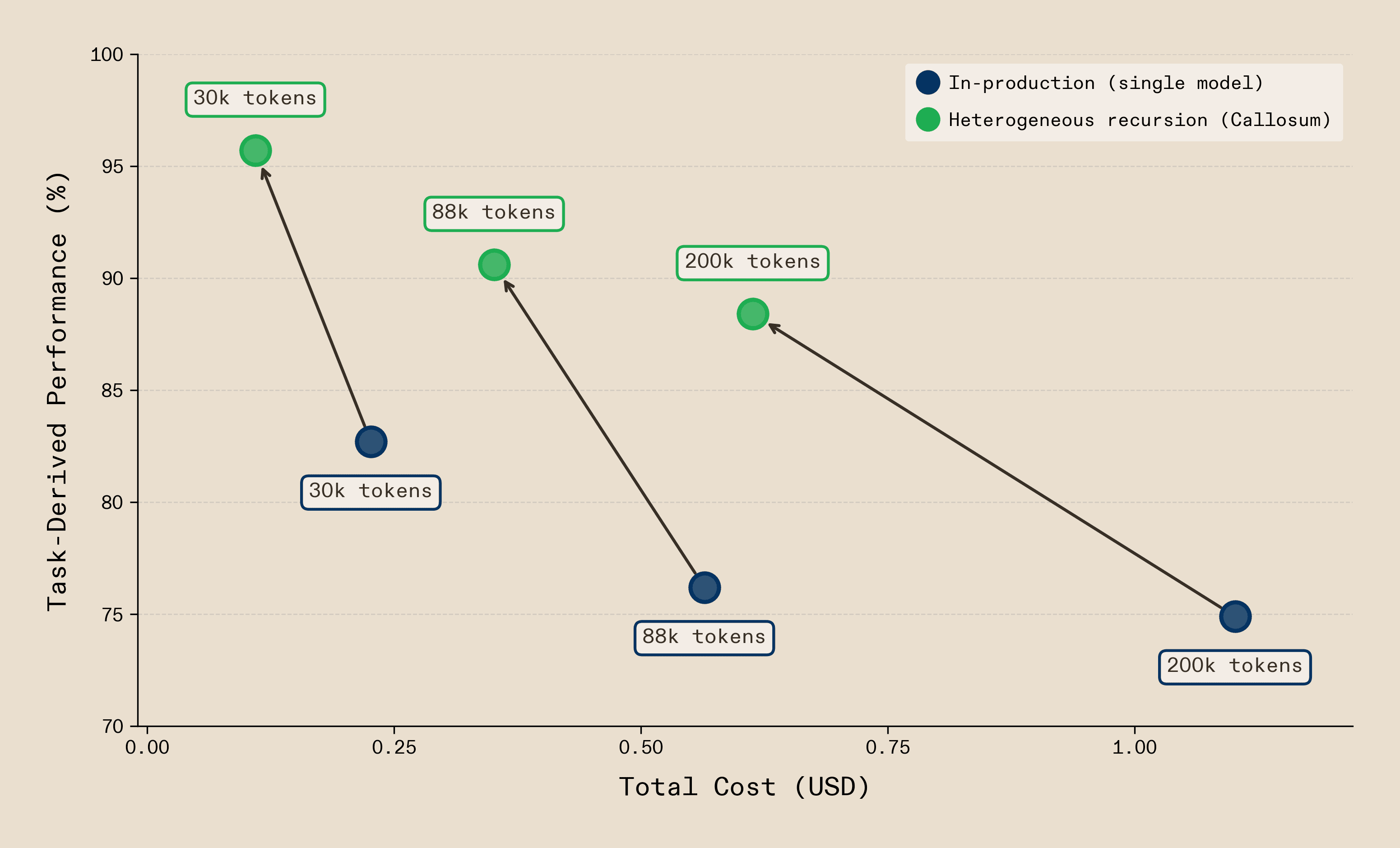
So what does this look like in practice? One of our partners, Coworker AI, whose autonomous agents handle millions of complex enterprise workflows, deals with this every day: generating status reports from raw activity logs, where contexts are long and noisy, signals are sparse, and the workflow demands retrieval, attribution, categorisation and strict formatting. These are precisely the kind of deep context problems heterogeneous recursion solves. We benchmarked their results on GitHub activity logs from the public vLLM repository. Callosum infrastructure clearly beats single-call Claude Opus 4.5 baselines across the board. At 30k tokens - well within range for a single call - Callosum is 2.1x cheaper with a +13 point quality improvement due to more accurate attribution of commits to contributors, fewer hallucinated entries and tighter adherence to the required output format. At 200k tokens, where single-call approaches degrade as critical signals drown in noise, we are 1.8x cheaper and +13.5 points higher quality.
Deep context isn't a frontier model problem. It's an orchestration problem - and heterogeneous recursion is how we're solving it.
Heterogeneous vision-language-action with active perception and multi-modal memory break state-of-the-art and generalises to cheaply automating payments.
In the previous section, the environment our infrastructure addressed can be thought of as a document - long, noisy, but ultimately relatively static text. The internet is a much more complex open-ended environment. Here, a single task can require visual perception, text comprehension, long-horizon planning, precise spatial targeting, and real-time adaptation to a live interface, all within a single workflow. Pages load unpredictably, layouts shift, elements appear and disappear. Crucially, no amount of reasoning alone can solve these problems. They require active perception, action, and continuous interaction with an environment that changes with every step.
Callosum's infrastructure treats the web the way it actually is - a heterogeneous environment requiring heterogeneous intelligence. The system maintains trajectory memory, allowing it to look back across its own history to verify decisions and replan when things go wrong. It holds visual working memory, tracking the precise spatial layout of the page so it can target the right button, the right link, the right field. It switches fluidly between visual and textual perception depending on what each decision demands such as reading a price as text, recognising a product from its image, interpreting a layout spatially. We gave our system an Umwelt - in biology, the perceptual world an organism constructs from what it needs to know. It doesn't perceive the web passively. It actively reshapes its own perception to match the task: switching to raw HTML when it needs structured data, zooming into a region to verify a UI element, scrolling to reveal what's hidden.
Through our system's discovery process, we quickly found that not every step needs the same model. Planning requires a large vision-language model with global context but verifying the coordinate of a small UI element (e.g., a rating button, a product link) does not. Before executing each action, the system zooms into the target region and routes this verification to a much smaller 8B model. This is heterogeneous intelligence at the level of individual actions: decompose the workflow, match each step to the smallest model that can solve it, and the gains compound across every decision in the trajectory.
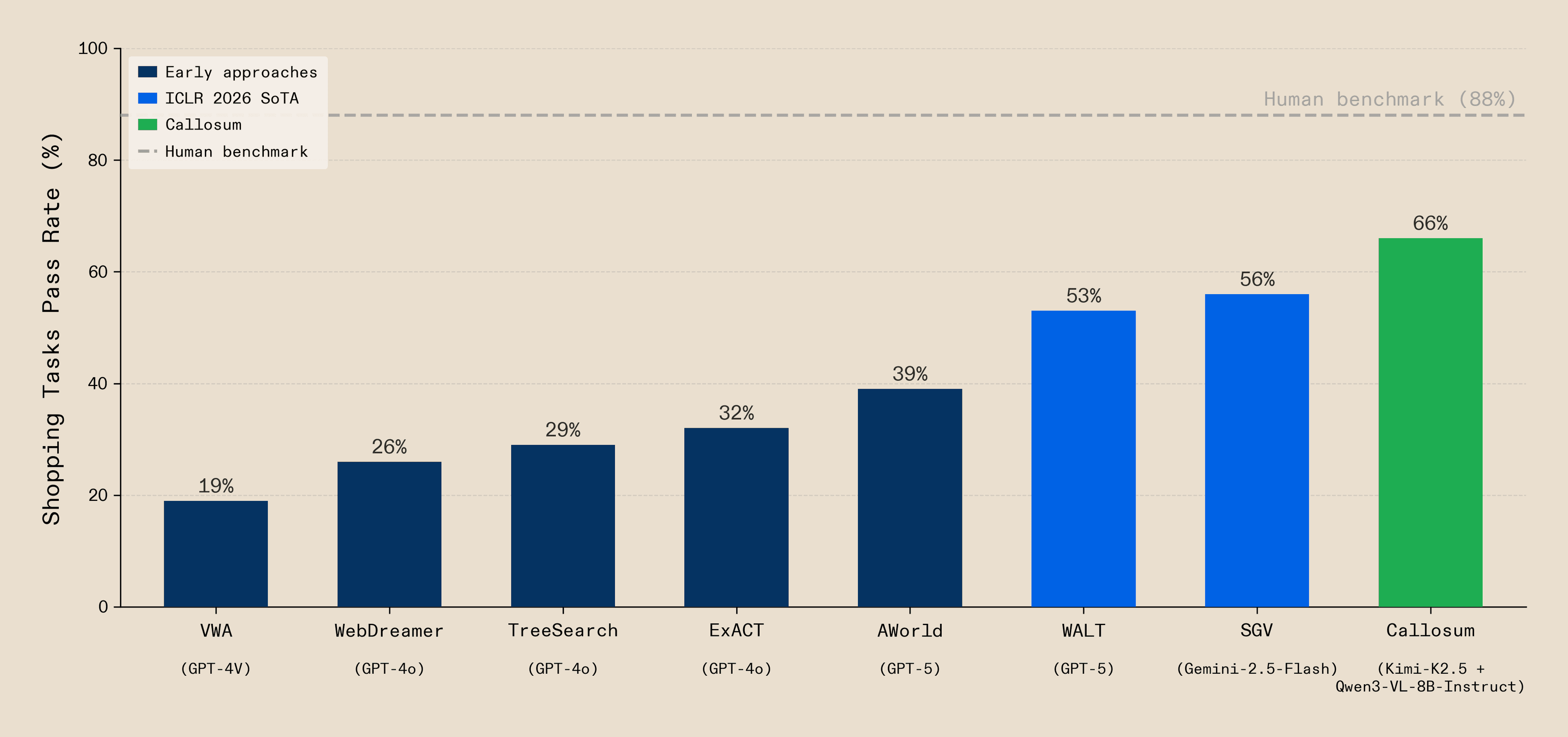
With our heterogeneous approach, we set a new state-of-the-art on Visual WebArena shopping tasks, surpassing the ICLR 2026 SOTAs with 1.18× the score of Self-Grounded Verification (SGV) and 1.25× the score of Web Agents that Learn Tools (WALT). We used only open-source vision-language-action models and no frontier API calls or proprietary models.
But the benchmark is the starting point, not our destination. What matters is that the system is already generalising to problems it has never seen. Consider asking our system:
"Find a robot in Amazon UK that looks similar to the one on the right of image 1, playing the ball as in image 2, from the same team of the player in image 2. Compare the price of the same product on OnBuy. If Amazon is indeed cheaper, purchase it with gift option and ship to our offices”
We actually tried it out. Here is the result:

This is an inherently heterogeneous task with multiple modalities, visual and text input processed by different network branches, long-horizon planning, self-verification and replanning across a live website. Text-only models cannot solve this and standard agentic frameworks struggle. Our system solves it because the same heterogeneous capabilities that broke the benchmark generalise.
Simply moving from homogeneous to heterogeneous configurations shifts the cost-latency Pareto frontier - and this holds across the open/closed model divide. By pairing a lightweight open-source vision model (Qwen3-VL-8B-Instruct) with either a frontier closed-source model (GPT-5.2) or a frontier open-source model (Kimi-K2.5), we achieve substantial reductions in both latency and cost without sacrificing task accuracy. The GPT-5.2 heterogeneous configuration is up to 3.7× cheaper (~$0.22 vs ~$0.83 per task) and 3× faster, as the smaller model not only reduces the latency and cost of zoom-in steps but also enables more accurate interactions that reduce the total number of steps required. The Kimi-K2.5 pairing shows the same pattern. The gains are model-agnostic: heterogeneous orchestration works whether the frontier model is open-source or closed-source, because the advantage is architectural, not a property of any single model.
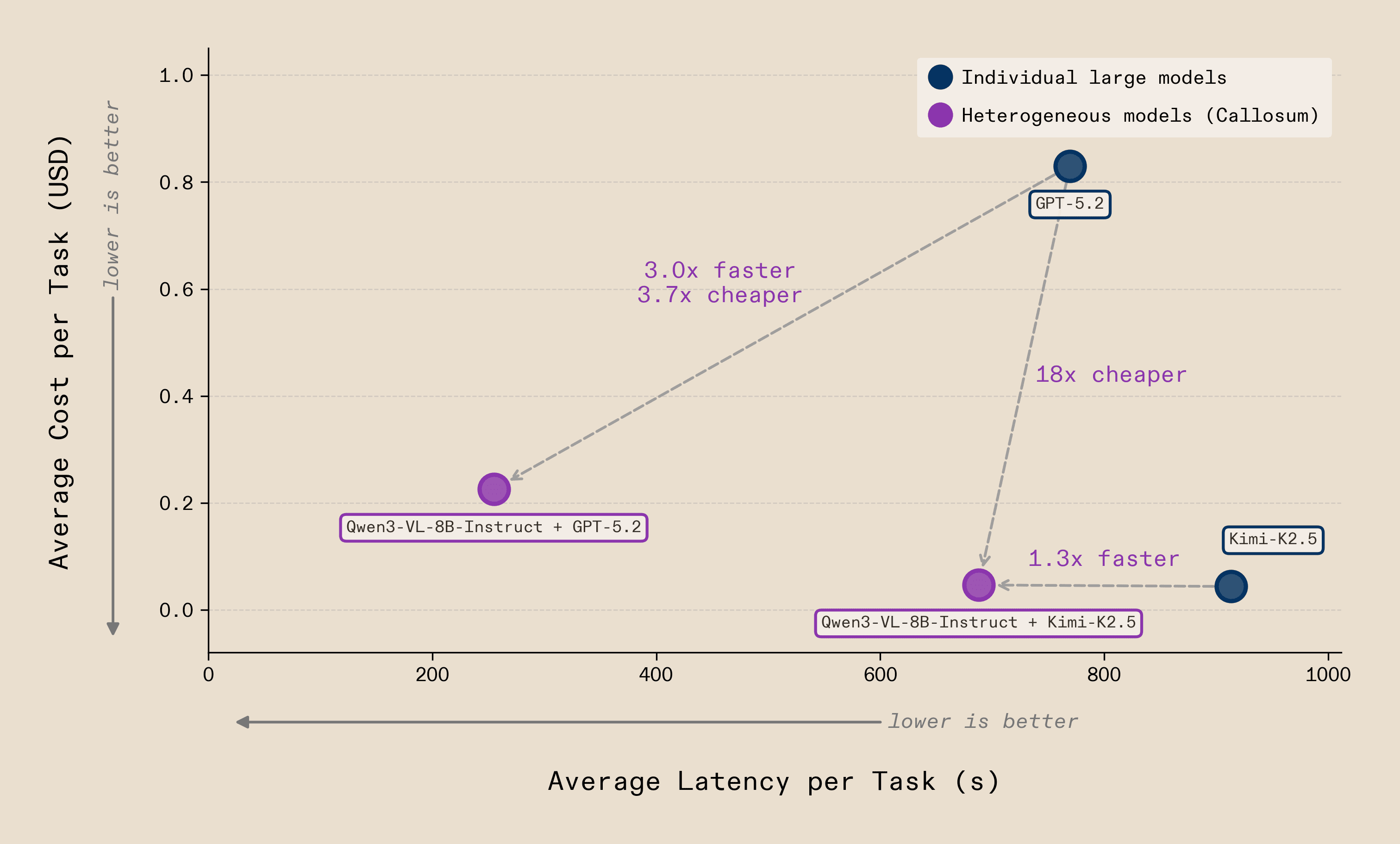
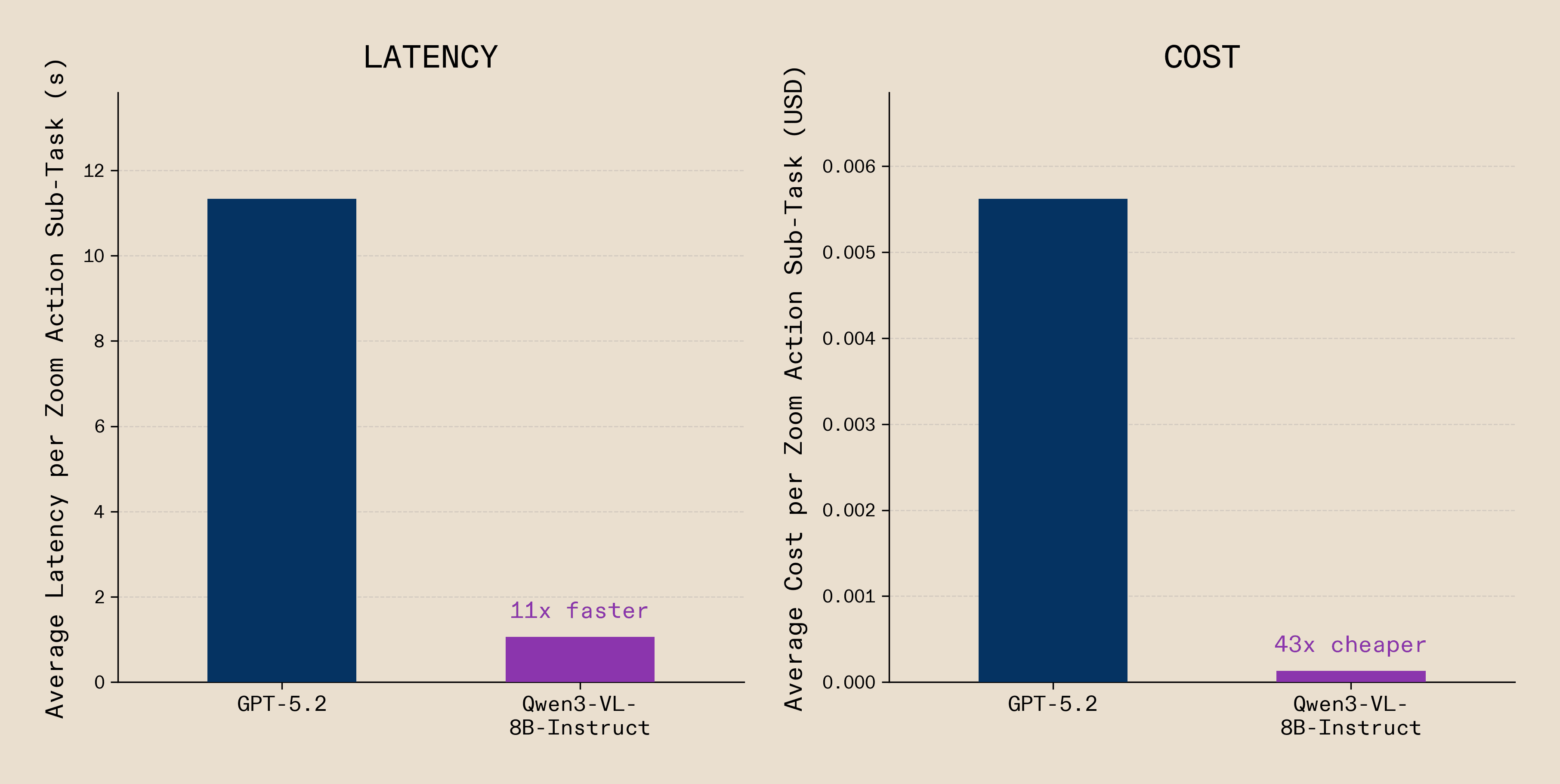
We also found that GPT-5.2 struggled particularly with reliable coordinate localisation; even with zoom-step assistance, it frequently selected wrong locations and failed far more often. Our infrastructure identified these failure points automatically and found that many were moments where the system must actively engage its environment rather than reason about it. These are precisely the steps where heterogeneity pays off most. On zoom steps alone, using a small 8B model achieved a 11x speedup and 43x cost reduction, from ~$0.0056 per zoom step with GPT-5.2 to ~$0.00013 while actually improving reliability.
The problems are heterogeneous and so the optimal system that solves them must be too. Mixed open-source vision-language-action models at different scales, each routed to the sub-task it's best suited for, orchestrated end-to-end through a single infrastructure.
Topology-aware cache management exploits heterogeneous complex workflow structure to eliminate redundancy.
The previous sections showed that we can discover the right decomposition of workflows across models and silicon through joint optimisation, unlocking performance that homogeneous systems cannot match. But as these systems scale - more models, more steps, more branching - a new cost compounds, redundant computation. In production, much of the work is predictable and repeated: the same pipelines, the same system prompts, the same reasoning chains executed over and over against changing inputs. Every inference call that recomputes tokens the system has already seen is wasted work.
When a language model processes a prompt, it builds an internal representation of every token - a key-value (KV) cache that stores what the model has "read" so far. This cache is expensive to compute and expensive to store. Caching lets the system reuse that work rather than rebuilding it from scratch on every call. But not every node in a workflow has the same cache profile - some carry large, frequently reused context, while others are lightweight and transient. When the cache fills up, something has to go. Today's eviction policies - Least Recently Used (LRU), Least Frequently Used (LFU) - are optimised for multi-user chat serving, not agents executing structured workflows. They treat every node identically, mistaking "used a while ago" for "no longer needed”. In an agentic workflow with predictable structure, this wastes compute. The execution graph already encodes what will be needed and when, but commonly used runtimes such as vLLM or SGLang do not exploit it.
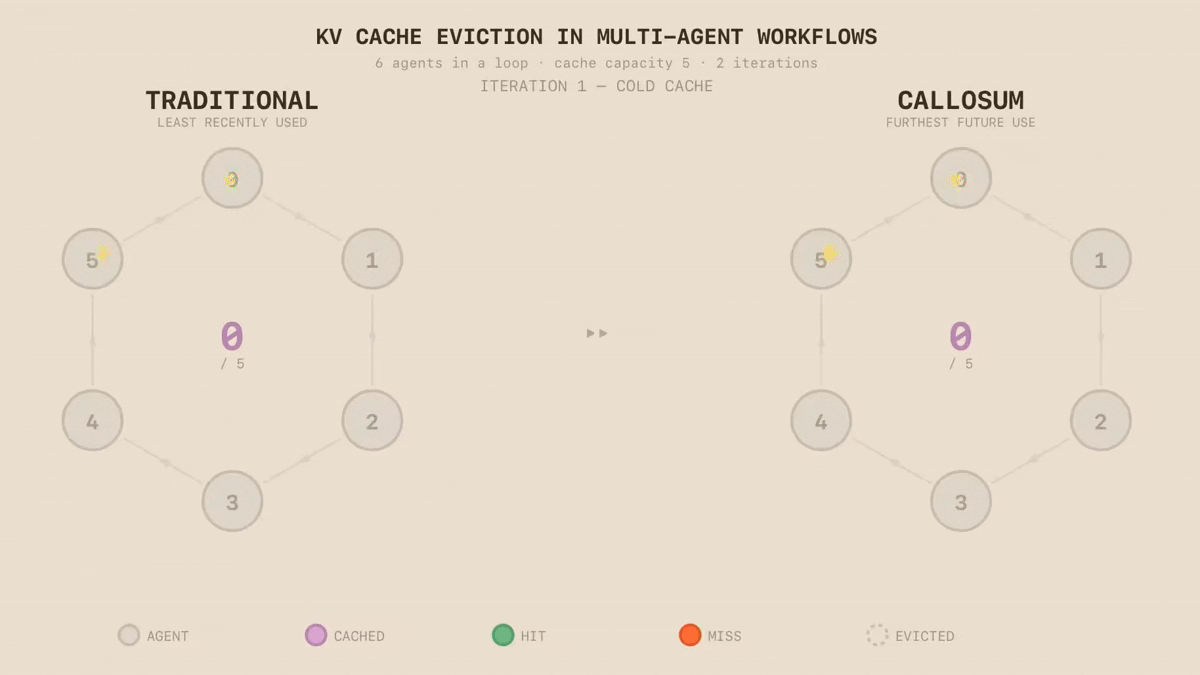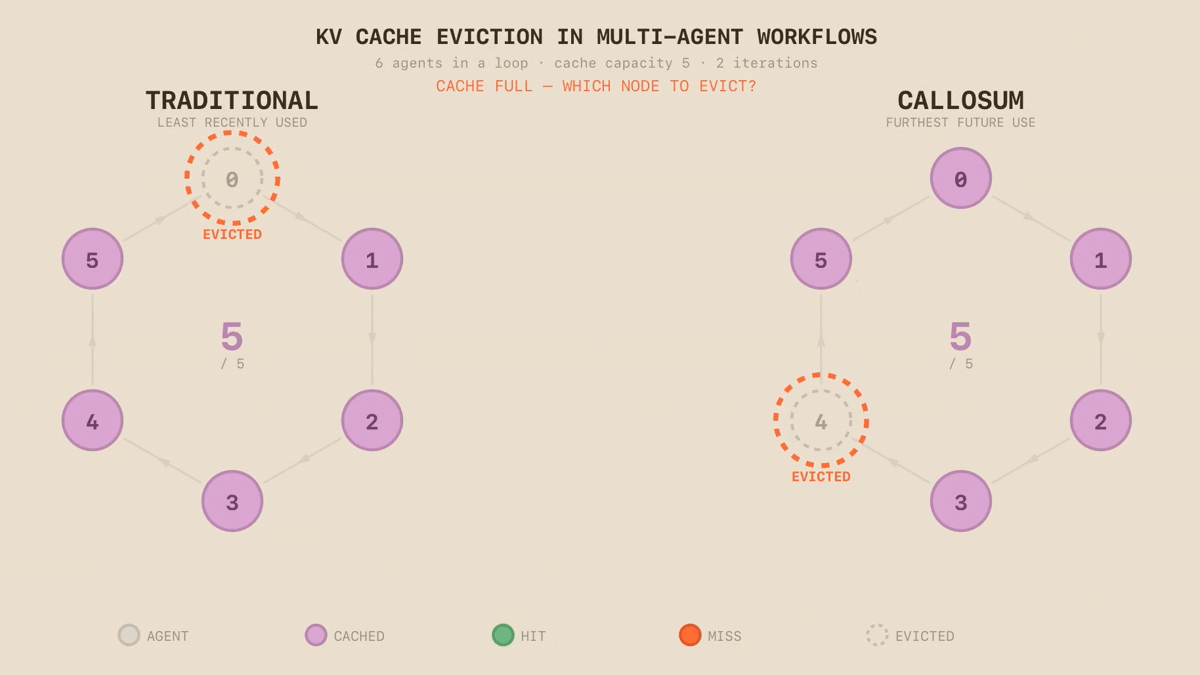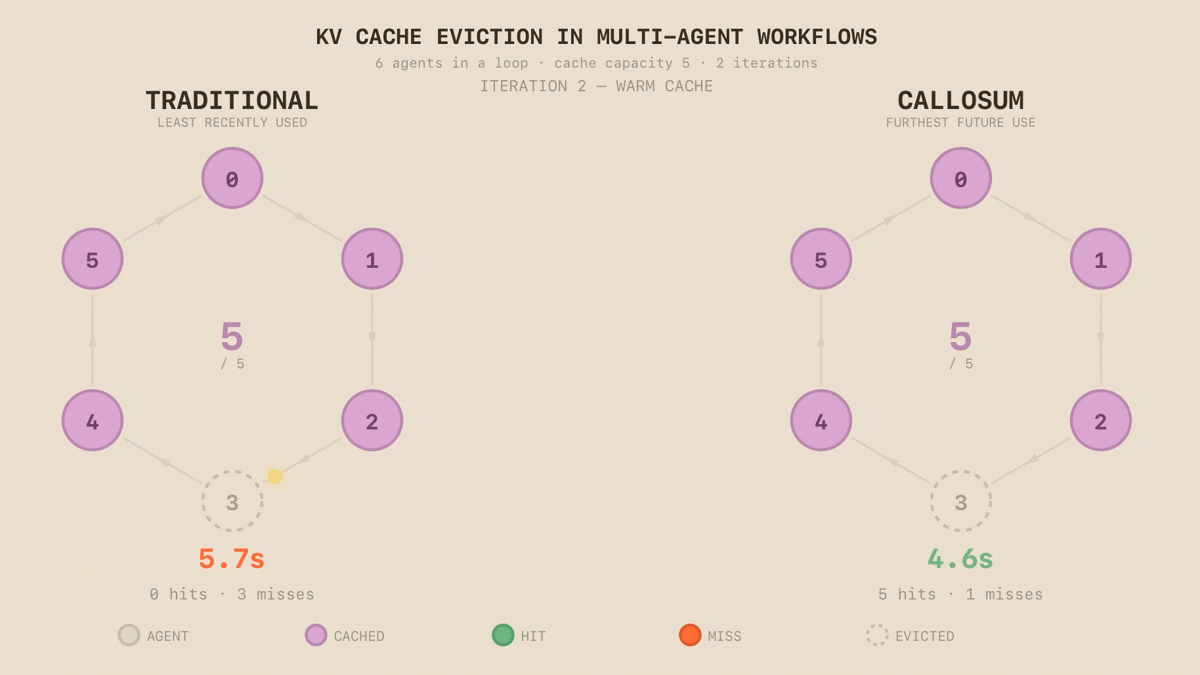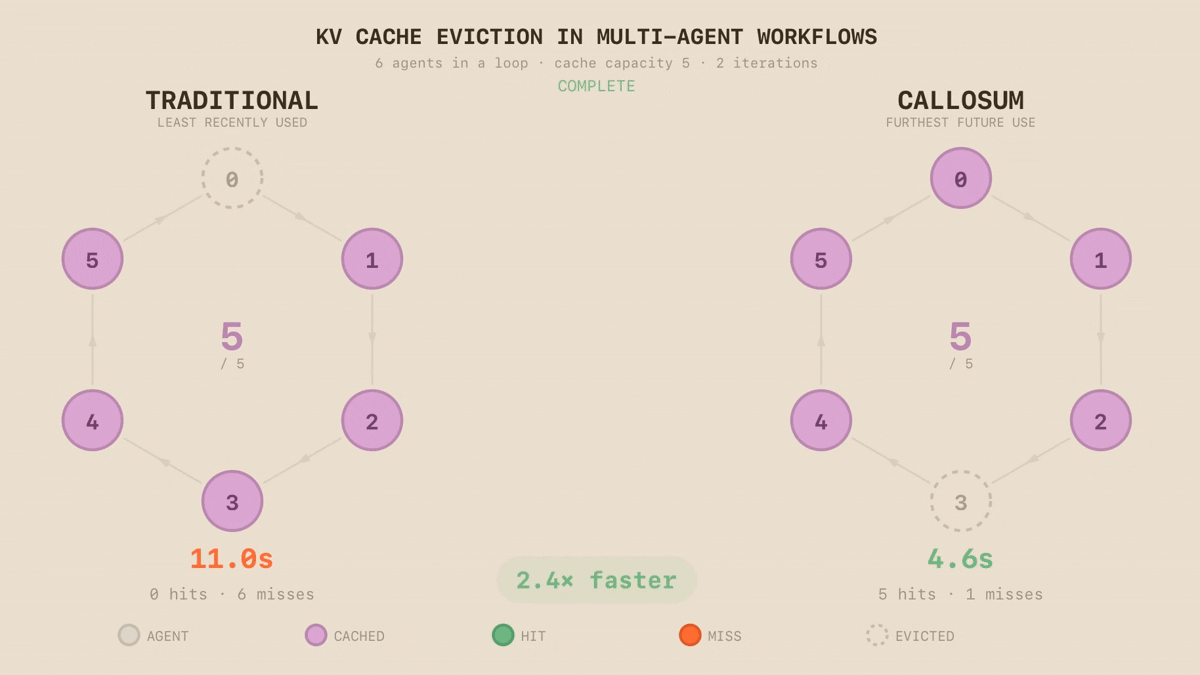
We replace heuristic eviction with topology-aware cache management: rather than evicting what was used longest ago, we exploit the execution graph to predict what will be needed, evicting the node furthest from future use. This is an instance of Bélády’s provably optimal eviction strategy, producing the fewest possible cache misses - a principle KVFlow demonstrated applies to agentic LLM systems. We turn this insight into a practical cache management policy. The difference is immediate: in a synthetic loop of six LLM calls with cache capacity for five, LRU evicts the node accessed longest ago - which in a loop is the next one needed. On the second iteration, LRU produces six cache misses. Our approach produces one. Eviction is just the beginning. As our runtime can see the workflow's topology, the same structural awareness enables pre-fetching context before it's needed, hierarchical caching across memory tiers and intelligent scheduling across different models on different silicon.
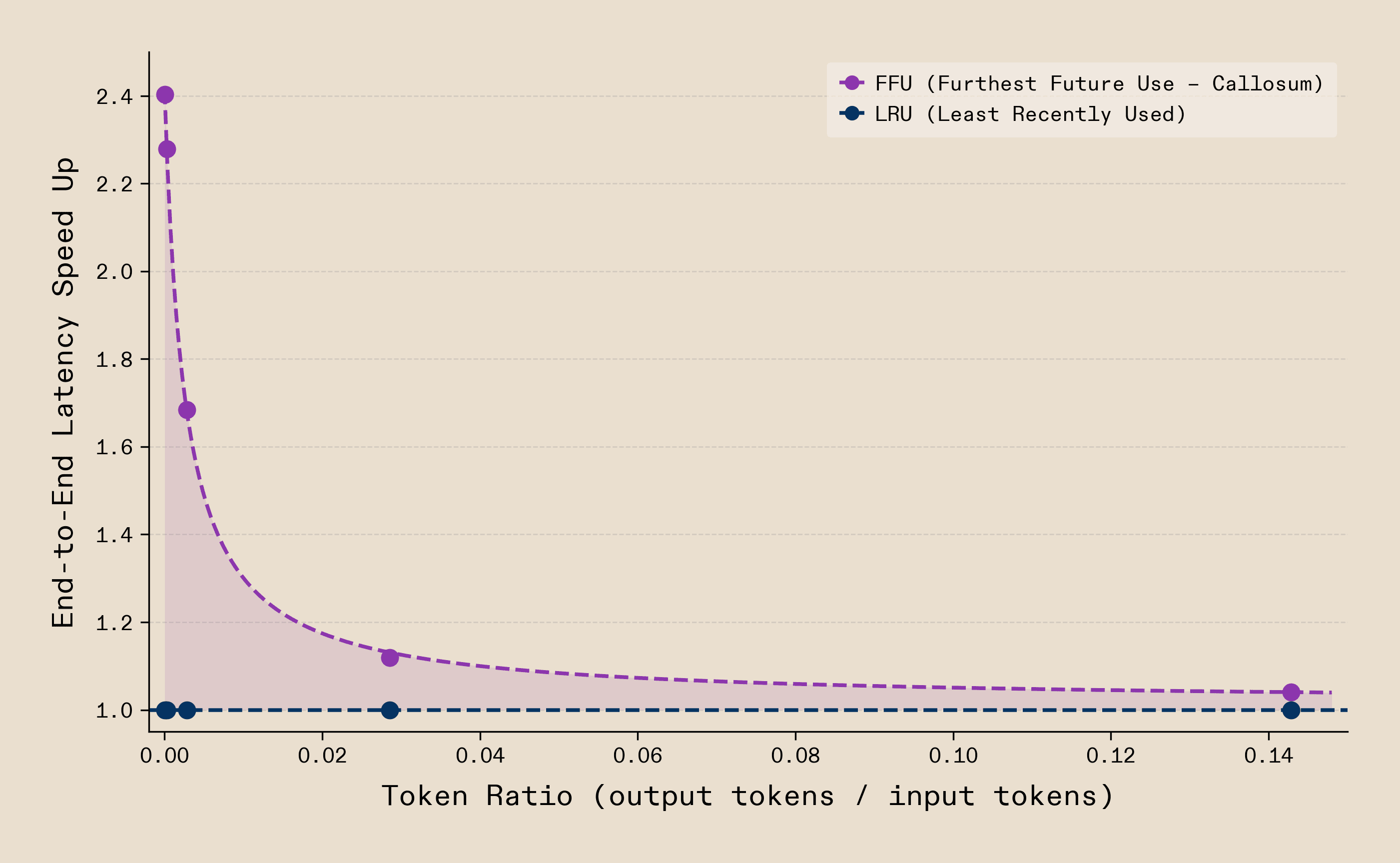
By isolating the relationship between output-to-input tokens for this workflow, we observe speedups of up to 2.4x in prefill-dominated regimes. This clearly illustrates what topology-awareness makes possible.
The gains here scale with the number of repetitions whenever there is a cache deficit - that is, when the workflow's cache demand exceeds the available hosted cache. This encompasses all but the most lightweight workflows, thus providing benefits where it really matters. The time savings (ΔT) scale linearly with the number of repetitions in the workflow (M) and hosted cache size (C), up to the point where C satisfies the full cache demand:
This is crucial for modern agentic workflows. The more complex and repetitive the workflow, the greater the advantage. This already extends to real-world problems. Generating a podcast-style interview between two characters, each with distinct personalities, requires detailed system prompts. Large inputs mean costly recomputation. With topology-aware eviction alone, we achieved an out-of-the-box 20% speedup - and this is before any of the deeper optimisations that topology-awareness unlocks.
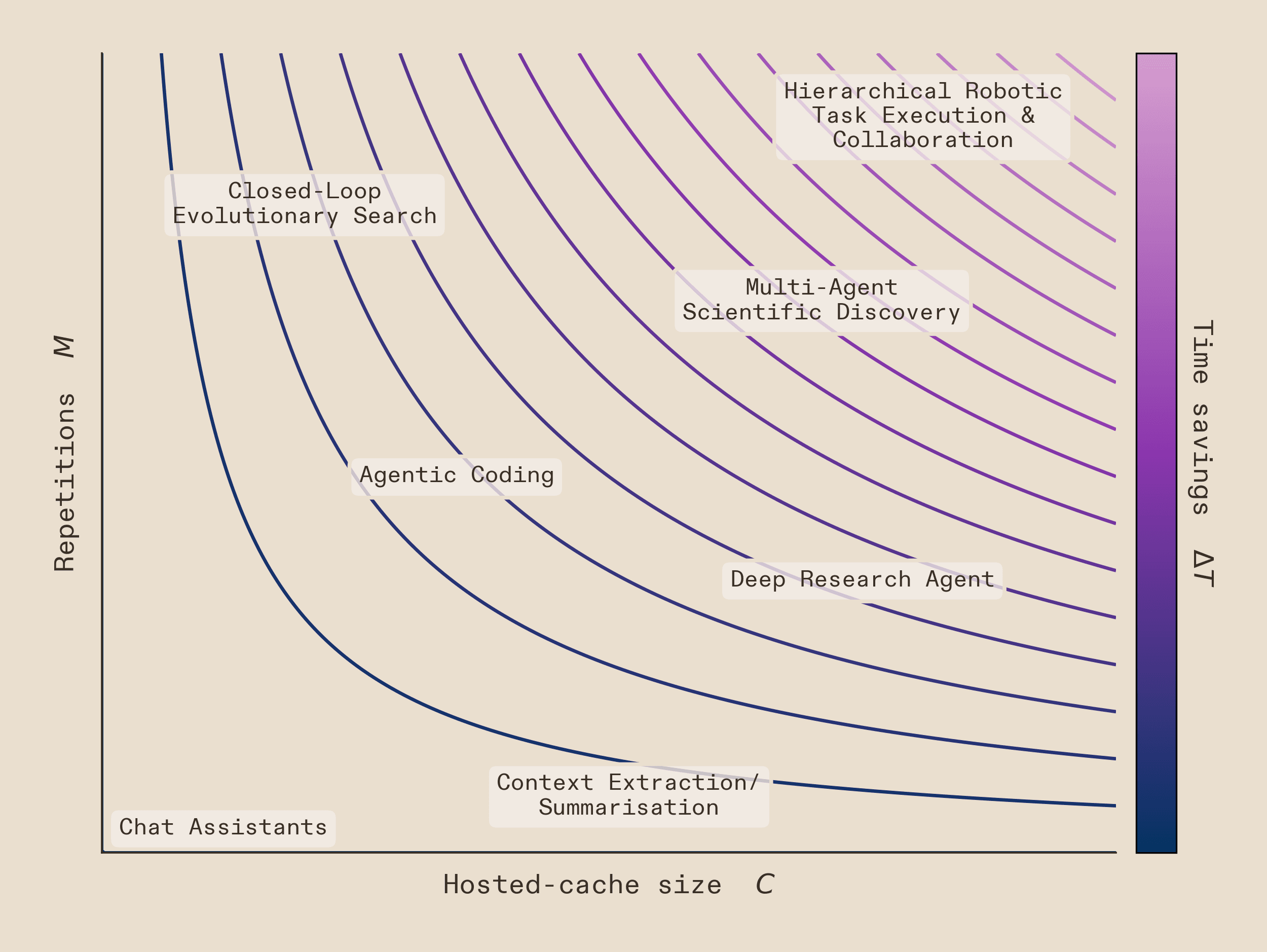
Topology-awareness is crucial for heterogeneous infrastructure. When workflows span different models on different silicon, each with different context lengths, memory capacities, and prefill costs, the execution graph is the only structure that unifies them. We are building a topology-aware runtime that reasons about cache residency across chips, predicts which nodes will be revisited across heterogeneous execution paths, and schedules prefills where they are cheapest. Cache eviction is where we demonstrate it first.
Every class of problem we've addressed so far shares a common dependency: tool calling. It is how heterogeneous agents act on the world. When a model queries a database, triggers an API, or hands off to another agent, it does so primarily through structured outputs - valid JSON conforming to a schema that defines what actions are available. As workflows grow in complexity, tool calling becomes critical. Get it wrong and the performance breaks. Get it right but too slowly, and the economics break instead.
Today, large models produce reliable tool calls but are slow and expensive. Small models are fast and cheap but unreliable. Neither scales in production. This is due to an architectural bottleneck: constraining model output to valid structure - known as grammar enforcement - is typically done in Python, on a CPU, round-tripping over the PCIe bus between processor and accelerator. Most open-source serving stacks work this way. The overhead scales linearly with batch size - O(B) - growing over 100x from batch 1 to batch 64, consuming up to 23% of the decode step. As serving scales, so does the grammar bottleneck.
Working closely with AWS Inferentia2 silicon, we moved the entire operation on-die. JSON schemas compile into finite state machines, and a custom NKI kernel performs constrained decoding entirely in NeuronCore SBUF. The mask lives in on-chip SRAM, right alongside the logits - no round-trip, no CPU involvement. The result is O(1) scaling: grammar enforcement adds 1.4μs at batch 1 and 1.7μs at batch 64 - 1,767x faster than CPU masking at the same batch size, under 0.01% of the decode step. Every token is guaranteed structurally valid by the finite state machine with no retries, validation, or wasted tokens.
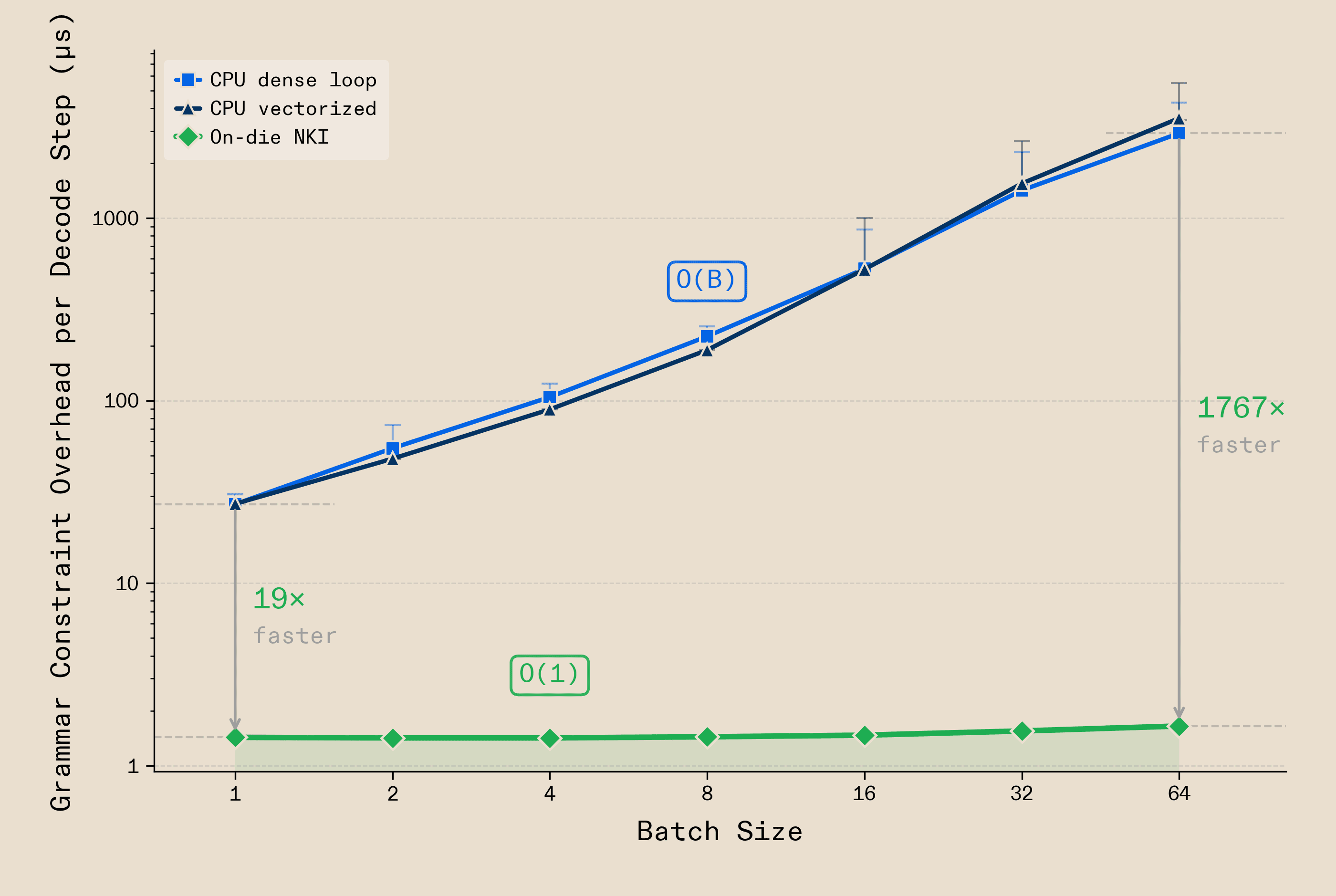
Despite this guarantee of structural validity, small models also struggle with semantic correctness - the actual content in the tool call being right - especially when compared to much larger models. Given this challenge, and the near-zero marginal cost of grammar enforcement as batch size increases, ensemble inferencing becomes very attractive. Under ensemble inferencing, multiple candidates generate simultaneously, each exploring different semantic completions of the same tool call. Where a single sample may be wrong, agreement across independent samples boosts quality.
This changes what small models can do. A 1B model generating eight grammar-constrained candidates with a naive selection schema achieves 42.27% cross-task accuracy on structured data extraction - pulling multiple numerical and descriptive fields from context - a +11 point improvement over a greedy pass from the same model and a +2 point improvement compared to an 8B model at an increased inference speed. The latency saved by on-die masking is what makes this possible: eight candidates run at comparable latency to a single baseline call, since the infrastructure overhead avoids scaling entirely.
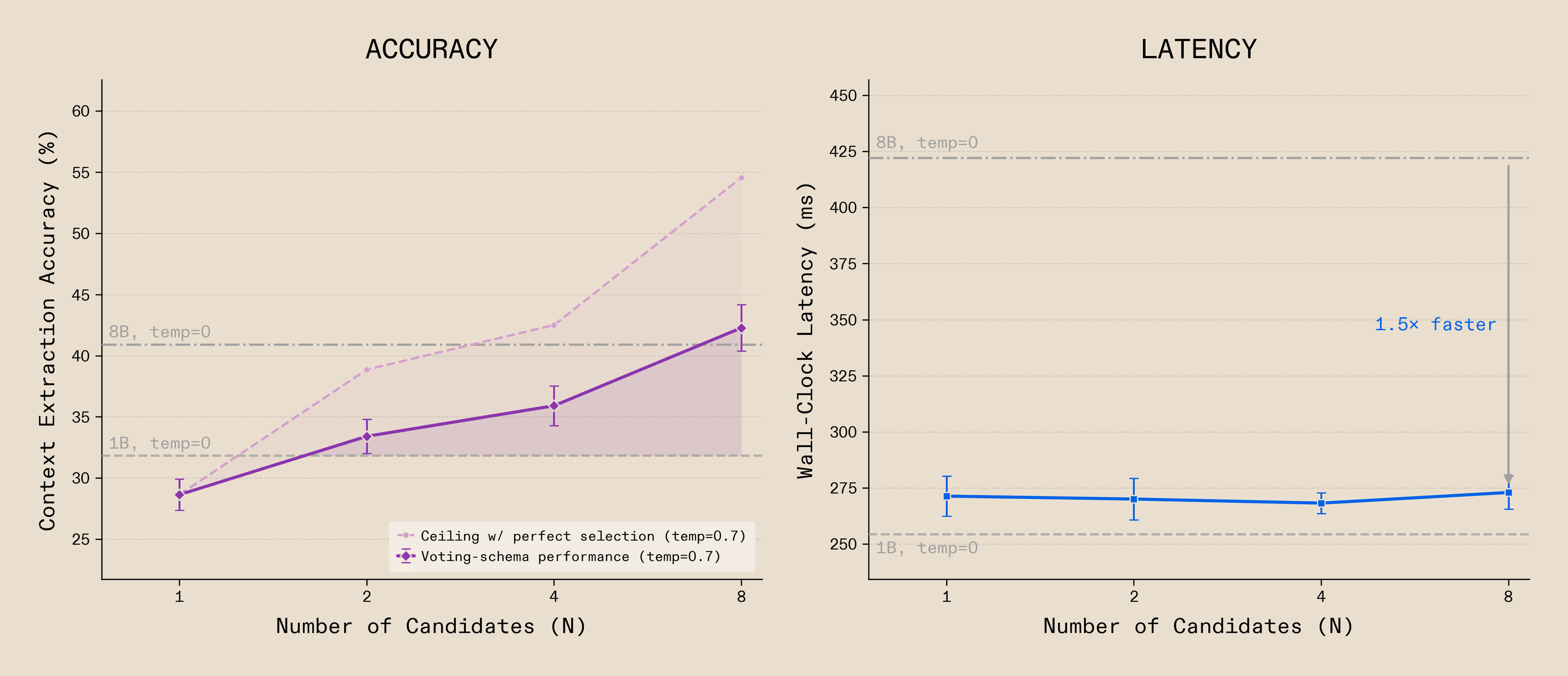
What this teaches us is that with the right infrastructure, the quality gap between small and large models is not fixed. Small models orchestrated intelligently can deliver capability parity with significantly larger models. By writing custom kernels that compile directly onto the NeuronCore, we give small models access to these strategies that were previously uneconomical. This is what full control of the silicon makes possible. The model does not need to be smarter. It needs more shots, and the infrastructure needs to make them free. The workflow knows what format is needed. The compiler knows what tokens are valid. The kernel enforces the constraint on silicon.
This is ensemble inference for tool calling on custom silicon and only scratches the surface of what becomes possible when intelligence and silicon are co-evolved.
Everything we've shown here is early evidence for a deeper thesis: as the problems we need to solve in the real world grow in difficulty and complexity, the systems that solve them must grow in diversity. Heterogeneous systems - diverse models on diverse hardware, co-evolved end-to-end - unlock scaling territory that homogeneous systems cannot access. In our next post, we formalise this into a theory.
The era of homogeneous scale delivered extraordinary progress. What comes next is Heterogeneous Intelligence - where models, workflows, and silicon co-evolve, and every new source of diversity makes the whole system smarter, faster, and cheaper. Every new dimension of heterogeneity we add compounds with every other. The configuration space is vast and we have only just begun to explore it.